
Gràcies a la contribució desinteressada de la comunitat catalanoparlant, el català ha superat les 1.000 hores enregistrades i les 900 hores validades al projecte Common Voice, com es pot comprovar en la nova versió del corpus de Common Voice publicada el passat 26 de gener. A més, hi han participat el Barcelona Supercomputing Center i Política Lingüística de la Generalitat de Catalunya en l’elaboració i recopilació de textos per a enregistrar. El Common Voice és un projecte clau per a garantir la presència del català en les noves tecnologies relacionades amb la veu, el reconeixement de la parla, la síntesi de veu, etc.
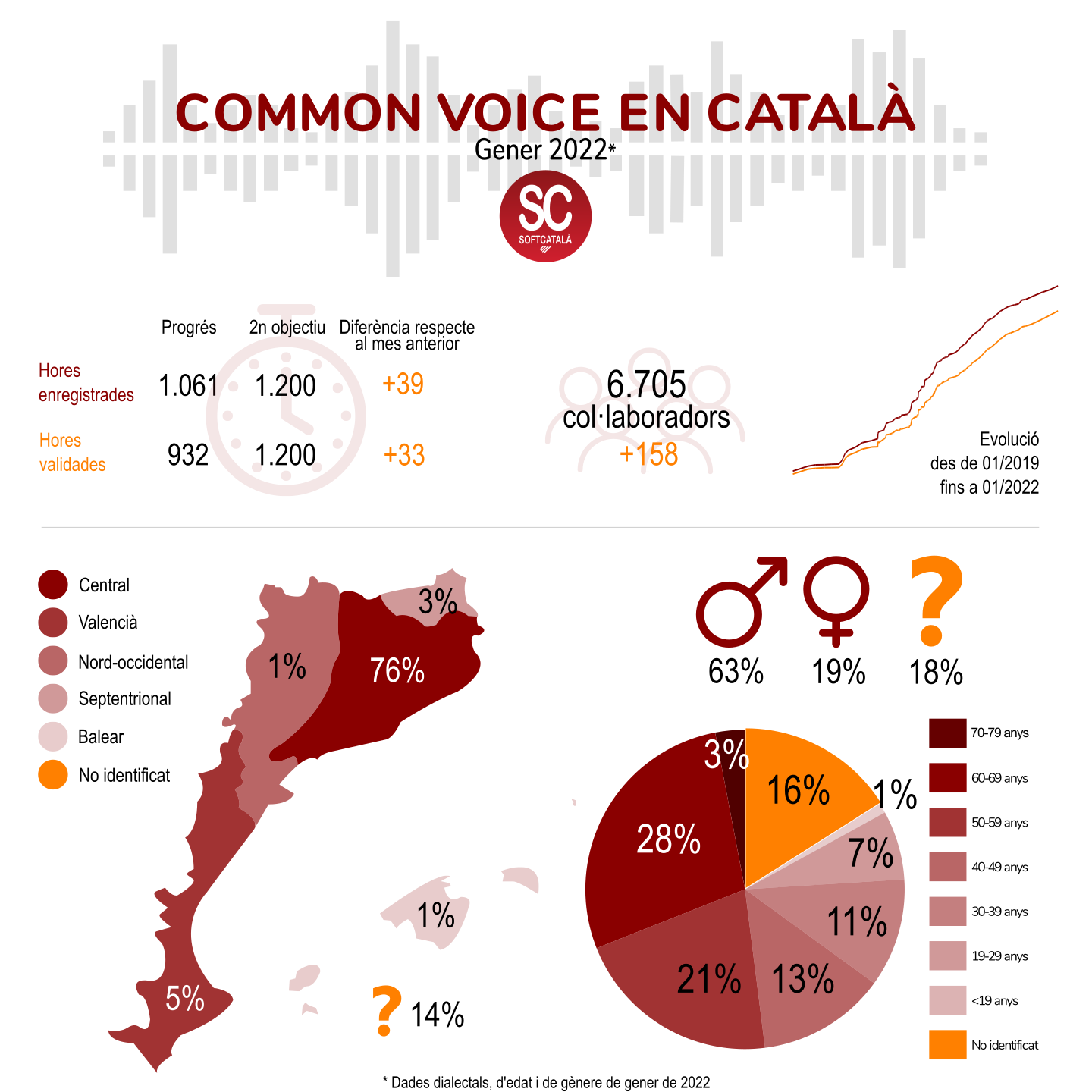
Estadístiques del català al Common Voice, gener de 2022.
Però, què és el Common Voice?
El projecte Common Voice és una iniciativa promoguda per la Fundació Mozilla, amb l’objectiu final d’aconseguir, entre altres coses, que la tecnologia i els aparells que funcionen amb ordres de veu reconeguin totes les llengües del món. D’aquesta manera, els assistents virtuals, els navegadors GPS i totes les tecnologies que utilitzen reconeixement o síntesi de veu podran entendre i parlar, entre d’altres, el català.
En què es basa el Common Voice?
Com ja us hem explicat altres vegades, el Common Voice crea una base de dades composta per parells d’elements relacionats: texts curts i talls de veu amb la lectura d’aquests texts. D’aquesta manera, si la base de dades de parells text-veu és prou gran, es pot utilitzar per a entrenar intel·ligències artificials relacionades amb el reconeixement de la parla, la síntesi de veu, etc. I com que és una base de dades oberta a tothom, qualsevol particular o empresa pot aprofitar-la per a incloure-la en els seus productes.
Podeu contribuir a fer créixer aquesta base de dades participant en el portal web gamificat del Common Voice en català.
La presència del català al Common Voice
La gran presència del català al Common Voice (posicionat entre les primeres quatre llengües durant molt de temps) ha portat a molts investigadors de fora a considerar el català en la seva recerca. El conjunt de dades de veu en català es pot fer servir per a moltes altres coses, a banda dels models de reconeixement de la parla. A continuació, es presenta un recull de les tasques objectiu i els models que s’han entrenat gràcies a les dades del Common Voice:
Reconeixement de la parla
- Model deepspeech/coqui:
- Models wav2vec2:
- Model Vosk/Kaldi:
Traducció de veu a text
- Català -> Anglès:
- Anglès -> Català:
- Multilingüe <-> Català
Traducció de veu a veu
També s’ha creat un corpus de paraules parlades que es pot fer servir per a entrenar models de detecció de paraules clau i podeu trobar aquí.
Quant a Softcatalà
Softcatalà és una associació sense afany de lucre que treballa per la normalització de la llengua catalana. Promouen el català en el sector informàtic, Internet i les noves tecnologies, a partir de la traducció de programari lliure i de distribució gratuïta. Per a més informació sobre els programes que aquesta associació ha traduït al català, podeu consultar el seu lloc web a https://www.softcatala.org.